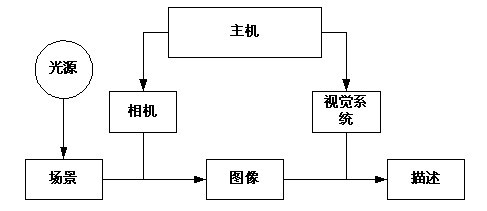
在创建瑕疵检测数据集时,数据的分割与划分是关键的步骤,以下是具体的方法和步骤:
1. 数据预处理:
将不同种类的图片分割成指定大小,这是为了建立统一规格的训练数据集,便于后续模型的处理和训练。
数据可能需要转化为特定的格式,如VOC或COCO格式,以便于后续的模型训练和标注。
2. 数据标注:

使用标注工具(如roLabelImg)对图片中的瑕疵位置进行标注,生成xml或其他格式的标注文件。
这些标注文件将用于训练模型,使其能够识别和定位瑕疵。
3. 数据集划分:
将数据集划分为训练集、验证集和测试集。训练集用于训练模型,验证集用于调整模型参数和验证模型性能,测试集用于最终评估模型效果。
数据集的划分比例可以根据具体需求和数据集大小来确定,常见的划分比例为7:2:1或8:1:1等。
4. 数据扩充:
如果数据集较小,可以通过数据扩充的方法来增加数据集的多样性和数量,如旋转、缩放、翻转等图像处理技术。
数据扩充有助于提高模型的泛化能力和鲁棒性。
5. 考虑标注方式和标签类别:
根据瑕疵检测的具体需求,选择合适的标注方式和标签类别。例如,对于多标签分割与检测任务,需要明确标注出不同瑕疵类型的标签。
标注方式和标签类别的选择将直接影响后续模型的设计和训练策略。
创建瑕疵检测数据集时,需要进行数据预处理、数据标注、数据集划分、数据扩充以及考虑标注方式和标签类别等步骤。这些步骤是确保数据集质量和后续模型训练效果的关键。